Smart Living Products
ISDN2001/2002: Second Year Design Project
Independent Study 2
Real-time Gesture Classification for Bow Drawing Detection Using MediaPipe Landmarks and Logistic Regression
By CHU, Siu Pong
Abstract
This project investigates whether a simple logistic regression classifier can accurately distinguish a bow-drawing posture from an idle standing posture using only 2D landmark data from MediaPipe. MediaPipe's 3D world landmarks are known to be noisy and unreliable, but even its 2D image-space landmarks are not perfect, as they can be affected by camera angle, distance, and partial occlusion. A dataset of 2000 images was collected for two classes, including 1000 drawing images and 1000 idle images. A total of 99 features were extracted from each image based on thirty-three body landmarks including coordinate information and visibility values. The logistic regression model was trained using seventy percent of the collected data and evaluated on the remaining thirty percent dataset. The trained model achieved over 95% accuracy on the test set, and a real-time inference script was built that classifies the user's posture from a webcam feed. The proposed method is not limited to bow drawing recognition, and it can be applied to any binary gesture classification task where the two poses are sufficiently distinct in the MediaPipe landmark space. The results demonstrate that reliable posture recognition can be realised with simple linear models and ordinary 2D visual data, which provides a lightweight and practical alternative to deep learning for specific gesture-control applications.
1. Introduction
Gesture recognition plays a vital role in modern human-computer interaction systems. In practical application scenarios such as game control and virtual reality interaction, it is usually sufficient to identify several fixed predefined poses instead of capturing continuous human body movement changes. This study mainly focuses on distinguishing two typical human postures, namely the bowdrawing posture with arms raised and pulled backward and the idle standing posture with arms naturally placed on both sides of the body. In this experiment, only a common desktop webcam was used as the data acquisition device. Different from deep neural network models which require massive training data and high-performance computing equipment, this research adopts a more concise technical scheme. MediaPipe pose estimation framework is adopted to extract two-dimensional body landmark coordinates from real-time camera images, and the extracted feature data is imported into a logistic regression classifier for posture judgment. This lightweight recognition framework can maintain stable real-time detection performance under conventional hardware operating conditions.
2. Background and Limitations of 2D Landmarks
MediaPipe pose estimation technology can complete real-time human body key point detection and output thirty-three standard body landmarks for each detected human target. Each landmark contains normalized horizontal and vertical coordinates in the image coordinate system, as well as visibility data reflecting the detection confidence of the key point. Although MediaPipe can also output estimated three-dimensional world coordinate data, such spatial information is completely inferred from singlechannel RGB images without actual depth data support, so it is easy to generate detection noise and spatial deviation, and cannot meet the requirements of accurate spatial position judgment. Therefore, this study only uses stable two-dimensional image space landmark data to carry out subsequent experimental research.
Two-dimensional landmark data also has obvious inherent defects in actual use. Since all coordinate values are normalized based on image size, the distribution of landmark points will be greatly affected by the shooting perspective of the camera. When the user changes the distance from the camera or slightly adjusts the body orientation, the two-dimensional projection position of the same physical posture will change significantly. Most traditional bow-drawing posture recognition methods rely on f ixed elbow angle threshold rules to complete classification judgment. This heuristic judgment method can achieve ideal recognition effect only when the camera is facing the user directly, and it is very easy to produce wrong classification results once the shooting angle is offset.
Compared with rigid angle judgment rules, the classification model constructed in this research can learn the overall distribution characteristics of body landmarks, so it has better anti-interference ability within a fixed shooting environment.


Fig. 1. Example of a camera angle causing a simple angle heuristic to misclassify the drawing pose, while the full landmark pattern remains distinct.
3. Method
3.1 Data Collection and Feature Extraction
All experimental sample data are captured through ordinary household webcams, and the whole dataset is kept in a balanced state with a total of 2000 valid images. Among them, 1000 images are used to record the standard bow-drawing posture, in which the user stretches one arm forward and pulls the other arm back to the side of the face. The other 1000 images record the daily idle standing posture with relaxed limbs. During the data collection process, MediaPipe runs in static image detection mode, and all images that fail to detect complete human body landmarks are eliminated. All qualified posture images are converted into 99-dimensional feature vectors by flattening processing, and each body landmark corresponds to three feature values including horizontal coordinate, vertical coordinate and visibility. In the whole feature processing process, additional data normalization operation is not carried out, because the training process of logistic regression will not be greatly affected by the difference of feature data range.
3.2 Model Training
This research selects logistic regression model to complete binary posture classification work, and the whole training process is completed by calculating linear fitting results, activating probability distribution, calculating loss error and optimizing model parameters. The model firstly completes the linear weighted fitting of all input feature data to obtain intermediate calculation results, and the specific calculation form is shown in Equation (1).
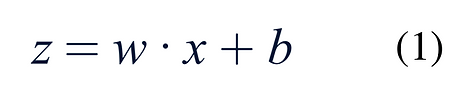
x denotes the 99-dimensional pose landmark feature vector extracted from MediaPipe detection results, while w is the trainable weight vector that assigns different importance degrees to each feature dimension. The symbol b represents the model bias term, which is used to adjust the overall output baseline of the linear calculation. The output value z is a preliminary linear fusion result prepared for subsequent probability conversion.
In order to convert the unlimited linear calculation results into probability values between zero and one that are convenient for classification judgment, all intermediate values will be imported into the sigmoid activation function for mapping processing, and the specific mapping rule is shown in Equation (2). Through Equation (1) and Equation (2), the model can convert complex high-dimensional landmark feature data into intuitive posture classification probability values.

This formula converts the unbounded linear result z into a predicted probability value p ranging from 0 to 1. The value of p represents the model estimated probability that the current input pose belongs to the bow-drawing class, which provides a measurable basis for f inal binary classification judgement.
In order to convert the unlimited linear calculation results into probability values between zero and one that are convenient for classification judgment, all intermediate values will be imported into the sigmoid activation function for mapping processing, and the specific mapping rule is shown in Equation (2). Through Equation (1) and Equation (2), the model can convert complex high-dimensional landmark feature data into intuitive posture classification probability values.
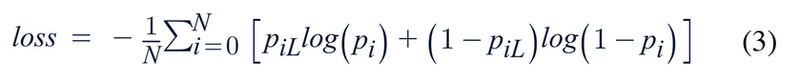
In this loss function, PiL stands for the ground truth label of each training sample, and Pi refers to the predicted probability obtained from the previous calculation. N indicates the total number of training samples used in each iteration. The calculated loss value reflects the overall deviation between model prediction results and actual labels, which acts as the core evaluation standard to judge model fitting performance.
After obtaining the overall loss error of the model, the gradient descent optimization algorithm is used to continuously adjust the internal weight parameters of the model, so as to gradually reduce the classification error and improve the overall recognition accuracy. The gradient value for parameter adjustment is calculated in Equation (4), and the actual weight modification is implemented following the rule illustrated in Equation (5). Combined with the error feedback result of Equation (3), the model can continuously iterate and converge to obtain the optimal classification weight parameters.

This formula calculates the gradient used for weight updating during model training. Pi and PiL are consistent with the definition in the loss function, representing predicted probability and true label respectively. xij refers to the j-th dimensional feature value of the ith sample. The average gradient calculated from all samples can accurately reflect the changing trend of loss function, and further guide the model to adjust internal weights to reduce classification error.

This formula defines the complete weight updating strategy. The learning rate controls the adjustment amplitude of weights in each iteration step, which maintains stable training progress. By subtracting the product of learning rate and calculated gradient from the original weight value, the model parameters are updated towards the direction that reduces overall loss.
In terms of experimental training settings, all sample data are randomly divided into training set and test set according to the ratio of seven to three, and fixed random seeds are set to ensure the repeatability of experimental results. The model adopts L2 regularization mechanism to effectively suppress the over-fitting phenomenon in the training process, and the maximum number of iteration training is limited to 1000 times to ensure that the model can complete convergence training within a reasonable time range.
3.3 Real-time Inference
This research develops an independent real-time posture detection program, which can load the trained logistic regression model and process continuous video stream data collected by the webcam. In the real-time detection stage, MediaPipe switches to video dynamic detection mode to improve the efficiency of key point recognition. All video frames are processed in the same feature extraction and vector construction mode as the training samples, so as to ensure the consistency of data distribution in training and testing stages. The final recognition result will be displayed on the real-time video screen together with the human body key point skeleton, and the reserved program interface can realize linkage control such as keyboard response after identifying the specified bow-drawing posture, which verifies the practical application value of the recognition system in interactive scenes.
4. Experiment and Results
In this experiment, about 600 images in the test set are used to complete the quantitative evaluation of the model performance. The experimental results show that the overall classification accuracy of the logistic regression model can reach more than 95%. Most of the individual wrong recognition situations occur in the transition state between the two postures, and the ambiguous limb position leads to the confusion of landmark feature distribution. In order to further verify the practical application advantages of the proposed method, this study makes a comparative test with the traditional angle threshold recognition method.
Vid. 1. Real-time bow drawing gesture classification demo: live webcam feed with MediaPipe skeleton overlay and instantaneous logistic regression prediction.
Vid. 2. Pure angle-calculation detection demo: the traditional heuristic elbow-angle judgment method.
It can be clearly observed from the comparison results that the single angle judgment method is extremely dependent on the standard shooting perspective. Once the camera angle changes slightly, the calculated joint angle data will deviate, resulting in frequent wrong judgments. On the contrary, the real-time detection program based on logistic regression can maintain a stable detection frame rate of more than 30 frames per second on ordinary computers, and can still complete accurate posture recognition under slight perspective changes, with strong practical stability.
5. Discussion
The high-precision recognition effect of the simple linear classification model fully proves that there is an obvious distinguishable boundary between the two types of posture feature data in the highdimensional landmark space. Compared with the single angle judgment standard that can only rely on local joint information, the logistic regression model can integrate all body landmark distribution features for comprehensive judgment, and the introduction of visibility data can also help the model eliminate the interference of blocked and out-of-frame key points.
At the same time, this research also has obvious experimental limitations. All training samples are collected under fixed camera positions and shooting angles, so the generalization ability of the model will be reduced when the shooting environment changes greatly. In addition, all experimental data come from a single tester, and differences in physical characteristics and dressing styles of different people will also affect the actual recognition effect of the model.
Even restricted by the above conditions, the overall technical framework still has strong extended application value. The landmark extraction combined with logistic regression classification idea can be directly applied to other binary gesture recognition tasks, and only needs to collect corresponding labeled posture samples to complete model retraining. This recognition scheme has the advantages of low computing power consumption, fast model training speed and simple deployment process, which is very suitable for lightweight human-computer interaction development work.
6. Conclusion
This study completes the construction of a real-time bow-drawing posture recognition system based on MediaPipe two-dimensional landmarks and logistic regression algorithm. Relying on 2000 balanced posture sample images to complete model training, the final recognition accuracy of the system on the test set is more than 95%, and it can run stably in real-time webcam detection scenarios. This research confirms the application value and existing limitations of two-dimensional landmark data in posture recognition. The scheme can work stably in a fixed shooting environment, but it is difficult to adapt to large-scale perspective switching scenes.
The most important thing is that the overall research idea can be widely extended to various binary posture recognition tasks, providing a simple and efficient low-cost solution for lightweight gesture control research. In future research work, the recognition range can be expanded to multi-category posture detection, and the trained recognition model can be imported into Unity game development projects to realize real hands-free interactive control functions.
References
[1] C. Lugaresi et al., "MediaPipe: A framework for building perception pipelines," 2019. [Online].
https://arxiv.org/pdf/1906.08172
[2] S. Menard, Applied Logistic Regression Analysis, 2nd ed. Thousand Oaks, CA: Sage, 2002.
[3] F. Pedregosa et al., "Scikit-learn: Machine learning in Python," Journal of Machine Learning Research, vol. 12, pp. 2825-2830, 2011. https://www.jmlr.org/papers/volume12/pedregosa11a/pedregosa11a.pdf